- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Auto Indexing versus Build Array
03-09-2006 10:18 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
This leads me to a question: Is using auto-indexing for the output of a For loop or While loop similarly more efficient (in terms of speed, memory usage, etc) than manually using Build Array? Or do they ultimately amount to the same thing?
(I know the best way would probably be to initialize an array and replace it element-by-element as the loop iterates, but that might not be an option here.)
03-09-2006 10:30 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
My understanding of LabVIEW's internals would lead me to believe that both approaches take about the same amount of time. I'd be interested in the results, though, if somebody ends up benchmarking it.
-D
03-09-2006 11:03 AM - edited 03-09-2006 11:03 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
depending of the size of your array I would use a mixed approach:
This way LabView doesn't need to call it's memory management system so often. The problem is Labview doesn't know which size your array will be. So it has to "grow" the array (nearly) each time you append a value to it. All this requires do make copies of or to move memory blocks...
Message Edited by GerdW on 03-09-2006 06:04 PM
GerdW
using LV2016/2019/2021 on Win10/11+cRIO, TestStand2016/2019
{kind=link}
03-09-2006 11:13 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I should add that the resaon this came up is that I have been considering the replacement of a big flat sequence in my program with a case structure (i.e., state machine). Only one frame/state generates data, though, meaning that if I use auto-indexing, I'll end up with zeroes in the output array when the other states are executing. Make sense?
03-09-2006 11:28 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
03-09-2006 11:54 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
03-09-2006 11:58 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
03-09-2006 12:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
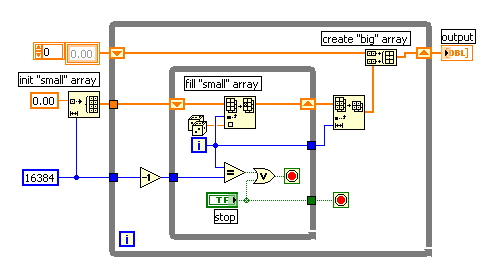
Here's a little benchmark. It test for and while loops, both with indexing and built array.
It gives really interesting results! It seems that Labview has a very smart optimizer built-in.
For iterations below 100 000 there isn't really much difference. All are very fast. The indexing loops are about twice as fast as the built array loops.
But above 100 000, strange things start to happen. The first time that you then run the benchmark, there's suddenly big differences. The indexed for loop stays equally fast. The indexed while loop suddenly becomes 10 times slower than the indexed for loop. When you run it a second time, than the indexed while loop is just as fast again as the for loop.
Seems to me that when using indexing, Labview creates a array of 100 000 elements before the loop, and then fills it. That's why it suddenly gets slower when you ask for a longer while loop. (It couldn't predict the size beforehand, like it can with the for loop. Apparantly... either the array stays in memory, or the optimizer remembers the previous number of iterations, because it runs much faster the second time.
The built array seems to be able to do something similar... But it stops at 250 000, when it start to get really slow in comparison to the indexing. At those numbers, running the program multiple times does not increase the speed for the built array loops.
Conclusion: for "small" numbers, Labview seems to be optimized far enough that it doesn't really matter.
For big numbers, indexing is much better than built-array. An indexing for loop is better than indexing while loop, but Labview can optimize very well when the number of iterations stays the same for multiple calls to the vi.
