Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- « Previous
- Next »
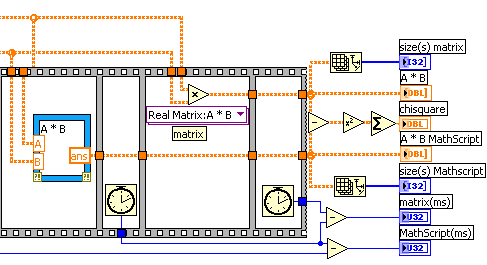
a lot of time to multiply two arrays
Active Participant
11-28-2005 08:28 PM - edited 11-28-2005 08:28 PM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
So I was playing with this again today to see if my new RAM would make
any difference. Didn't do anything for the matrix calculation (maybe
with a much larger matrix) and seemed to take about the same time to
startup LV8 
But one thing I did notice is that when you connect a matrix data type to a standard function like the 'multiply', it actually gets replaced with a polymorphic VI. This seems to be true with all the functions. So underneath the hood the standard multiply function is using the the "A x B.vi". Go ahead, just double click on it and see for yourself.

Ed Dickens - Certified LabVIEW Architect
Lockheed Martin Space
 Using the Abort button to stop your VI is like using a tree to stop your car. It works, but there may be consequences.
Using the Abort button to stop your VI is like using a tree to stop your car. It works, but there may be consequences.
But one thing I did notice is that when you connect a matrix data type to a standard function like the 'multiply', it actually gets replaced with a polymorphic VI. This seems to be true with all the functions. So underneath the hood the standard multiply function is using the the "A x B.vi". Go ahead, just double click on it and see for yourself.
Message Edited by Ed Dickens on 11-28-2005 08:34 PM
Ed Dickens - Certified LabVIEW Architect
Lockheed Martin Space
Using the Abort button to stop your VI is like using a tree to stop your car. It works, but there may be consequences.{kind=link}
Active Participant
11-29-2005 10:22 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi all,
Thought I might jump in here and cover some of the differences between LabVIEW versions and the underlying linear algebra code. Prior to LabVIEW 7.1, all linear algebra functionality was computed in lvanlys.dll, using code that was developed in-house. Beginning with LabVIEW 7.1, lvanlys.dll now calls into Intel's MKL library. The Intel libraries use a lot of techniques to wring performance from their implementation. For example, blocking the algorithm to preserve data locality in the caches. Also, where available the libraries use the vector instruction set (SSE, SSE2, etc.). Check out Intel's website for details. For large matrices this really makes a big difference in execution speed, as demonstrated in this example. For small problems (e.g. 10x10) there can actually be a slight decrease in performance as compared to LabVIEW 7.0, but the execution time is so small for this problem size anyway that it is typically not an issue.
-Jim
Thought I might jump in here and cover some of the differences between LabVIEW versions and the underlying linear algebra code. Prior to LabVIEW 7.1, all linear algebra functionality was computed in lvanlys.dll, using code that was developed in-house. Beginning with LabVIEW 7.1, lvanlys.dll now calls into Intel's MKL library. The Intel libraries use a lot of techniques to wring performance from their implementation. For example, blocking the algorithm to preserve data locality in the caches. Also, where available the libraries use the vector instruction set (SSE, SSE2, etc.). Check out Intel's website for details. For large matrices this really makes a big difference in execution speed, as demonstrated in this example. For small problems (e.g. 10x10) there can actually be a slight decrease in performance as compared to LabVIEW 7.0, but the execution time is so small for this problem size anyway that it is typically not an issue.
-Jim
Trusted Enthusiast
11-29-2005 01:01 PM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi, Jim,
It means realization of matrix multiplication different in Intel MKL and Intel IPP libraries?
Why it so slow when ippmMul called for Intel IPP library?
Andrey.
It means realization of matrix multiplication different in Intel MKL and Intel IPP libraries?
Why it so slow when ippmMul called for Intel IPP library?
Andrey.
Active Participant
11-29-2005 02:02 PM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi Andrey,
I don't have any direct experience with the Intel IPP libs, but in looking at their manual I noticed that the matrix operations claim to be optimized for very small sizes, probably to support the specific sub-problems encountered in image processing and gaming applications. The matrix sizes that are listed as highly optimized are:3x3, 4x4, 5x5, and 6x6. This is a very different use case than that targeted by MKL. MKL is intended for larger problems and optimizes accordingly.
-Jim
I don't have any direct experience with the Intel IPP libs, but in looking at their manual I noticed that the matrix operations claim to be optimized for very small sizes, probably to support the specific sub-problems encountered in image processing and gaming applications. The matrix sizes that are listed as highly optimized are:3x3, 4x4, 5x5, and 6x6. This is a very different use case than that targeted by MKL. MKL is intended for larger problems and optimizes accordingly.
-Jim
- « Previous
- Next »
