- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Can tdms streaming vi's be used in LabVIEW Realtime?
09-18-2007 10:25 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Sorry for the confustion,
Depending on the backplane you have either 92kbyte or so or 192kbyte or so of FPGA memory for your DMA buffer. Fortunately, you will need only 1kbyte for your 2 channel application. This is the DMA block that you configure and access in FPGA.
On the RT side, you will want to configure the DMA buffer to say 4M. Once your read completes, use the scaling VIs in the LabVIEW/examples/compactRIO/shared folder to apply calibration constants and to scale to voltage. You can then scale to engineering units.
In the read loop, you have one loop that checks the amount of data in the DMA buffer and if it is not enough, you sleep for say 20ms. Once there is enough, you terminate the wait loop, read the data from the DMA buffer, scale it, and write it into a QUEUE.
You have another loop that pulls data from the QUEUE and writes it to the TDMS files. The QUEUE allows these two loops to operate in parallel and the QUEUE provides a FIFO buffer between the two loops - the producer which reads data from the DMA read, and the consumer which stores the data. You can also use a RT FIFO instead of a QUEUE.
Hope this helps
Solutions Manager, Industrial IoT: Condition Monitoring and Predictive Analytics
cbt
512 431 2371
preston.johnson@cbtechinc
09-18-2007 12:30 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
09-18-2007 01:01 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I think your scan rate is the key factor. If you want 2 seconds of data and 100kSA/sec, you need to run your I/O module at 100kHz. Move this data point by point into the DMA buffer on FPGA.
Set your read DMA on the RT controller to read 400,000 points (2 points from each channel). the read will now return two seconds of data. Since the data in the DMA buffer is 4bytes per point, you need 1.6MB DMA buffer size. I would alloccate 3.2MB to give you some head room.
Solutions Manager, Industrial IoT: Condition Monitoring and Predictive Analytics
cbt
512 431 2371
preston.johnson@cbtechinc
09-18-2007 01:28 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
09-18-2007 01:36 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Solutions Manager, Industrial IoT: Condition Monitoring and Predictive Analytics
cbt
512 431 2371
preston.johnson@cbtechinc
09-20-2007 06:29 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
09-21-2007 10:28 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
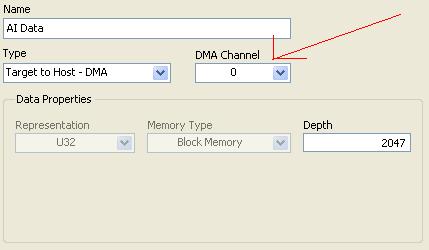
The other optimization is to consider the width of the FIFO. They are 32 bits wide. If you are sending data that can be represented in 16 bits, you can effectively send two channels on one FIFO. If you can represent your data in 8 bits, you can send all your data in one FIFO.
These are my best suggestions to implement your task.
09-21-2007 10:44 AM - edited 09-21-2007 10:44 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Message Edited by Bassett Hound on 09-21-2007 10:44 AM
{kind=link}
04-11-2008 01:06 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hey Bassett,
I'm interested in the DMA method you mentioned in one of your posts...
>Each DMA transaction has overhead, so reading larger blocks of data is typically better. The DMA FIFO.Read function automatically waits until the Number of >Elements you requested becomes available, minimizing the processor usage. However, cpu usage may increase if the data is coming in at a slower rate. This is >because the heuristics used in the DMA API to determine when to sleep or to poll depend on the amount of data and number of elements still coming. If its small it >might still spin and drive up the cpu usage. Its better to use some mechanism to ensure data \space is available, rather than relying on the blocking behavior on the >host DMA nodes. I manage this by using interrupts, timed loops, polling by reading 0 elements, or scheduling followed by polling.
Can you point me to an example that uses interrupts as you described here?
Steve
CLD
-------------------------------------
FPGA/RT/PDA/TP/DSC
-------------------------------------
04-14-2008 05:11 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
You can find examples on interrupt and polling synchronization in the LabVIEW example finder. To get to these examples go to the help menu in LabVIEW and click on "Find Examples..." Once in the example finder, go to Hardware Input and Output » CompactRIO (or R-Series) » FPGA Fundamentals » Host Synchronization
National Instruments
Applications Engineer
