- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Count number of occurrences in a table
12-14-2007 02:53 PM - edited 12-14-2007 02:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Message Edited by Sendtohen on 12-14-2007 02:56 PM
12-14-2007 04:07 PM - edited 12-14-2007 04:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Attached is a little vi that will take in an array of numbers, like your example...
1
1
1
2
2
3
and return the answer you are looking for. Unfortunately the vi is in 8.2 as I do not have version 7.x. Perhaps someone will be able to convert it for you.
Cheers!
Message Edited by jmcbee on 12-14-2007 03:17 PM
12-14-2007 04:10 PM - edited 12-14-2007 04:18 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
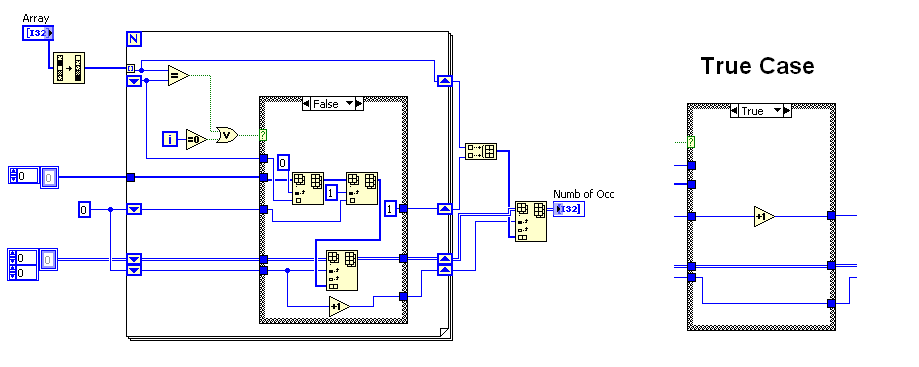
Here is an image of the block diagram to get you started. This program also assumes that you have read the excel file into labview and have created a 1D array of I32 values out of the data.
-Cheers!
Message Edited by jmcbee on 12-14-2007 03:11 PM
Message Edited by jmcbee on 12-14-2007 03:16 PM
Message Edited by jmcbee on 12-14-2007 03:16 PM
Message Edited by jmcbee on 12-14-2007 03:18 PM
{kind=link}
12-14-2007 07:59 PM - edited 12-14-2007 08:08 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
- Simpler, more compact, and easier to read code.
- No need to keep track of insert points, eliminating a shift register.
It can probably be simplified even more.

(TRUE case just does a +1 on the lower shift register wire.)
Message Edited by altenbach on 12-14-2007 06:08 PM
{kind=link}
12-17-2007 09:34 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Does "insert into array" create a copy of the data the same way that "build array" does? I was trying to avoid doing this in a loop, but perhaps "insert into array" does it anyhow.
Cheers!
12-17-2007 10:04 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
12-17-2007 01:45 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
12-17-2007 01:45 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
